Hoy día encontramos diferentes “topics” tecnológicos que tienen un gran impacto en nuestra sociedad, como por ejemplo la ciberseguridad, el big data o la inteligencia artificial. Una cosa común entre todas ellas son los datos. Los ciberataques en general se realizan para robar datos, mientras que el big data y la inteligencia artificial utilizan grandes cantidades de datos para extraer información y “enseñar” a programas a realizar una tarea, respectivamente.
Y es que que vivimos en la era de los datos. De hecho, como vemos en la siguiente figura, cada minuto (si he dicho minuto) generamos enormes cantidades de datos en todo el mundo: 500 hrs de YouTube subidas cada minuto, 42 millones de mensajes se intercambian por WhatsApp cada minuto, o se consumen más de 400.000 horas en Netflix cada minuto. Increíble.

Ya hace un tiempo comentamos aquí que los datos son considerados el petróleo del siglo XXI (https://cienciacarbonica.es/los-datos-el-petroleo-del-siglo-xxi/) y son muy valiosos y codiciados (como en el caso de los ciberataques).
Y es que la transformación digital ha acelerado su producción en los últimos años, con enormes beneficios, por ejemplo, en el ámbito de la salud (https://cienciacarbonica.es/la-transformacion-digital-en-la-salud/). Sin embargo, para que los datos generen información, conocimiento y finalmente sabiduría, éstos se han de procesar adecuadamente o pueden no ayudarnos a cumplir nuestros objetivos.
Y para entender esto, os pongo el siguiente ejemplo (inspirado en el trabajo de nuestro compañero Antón Camarero). Consideremos una vaca como los “datos crudos”, es decir, sin procesar. Pues estos datos se han de procesar adecuadamente dependiendo de la finalidad para los que queramos utilizar. Es decir, que a partir de una vaca, podemos sacar leche para hacer queso, o simplemente comernos su carne, por ejemplo.
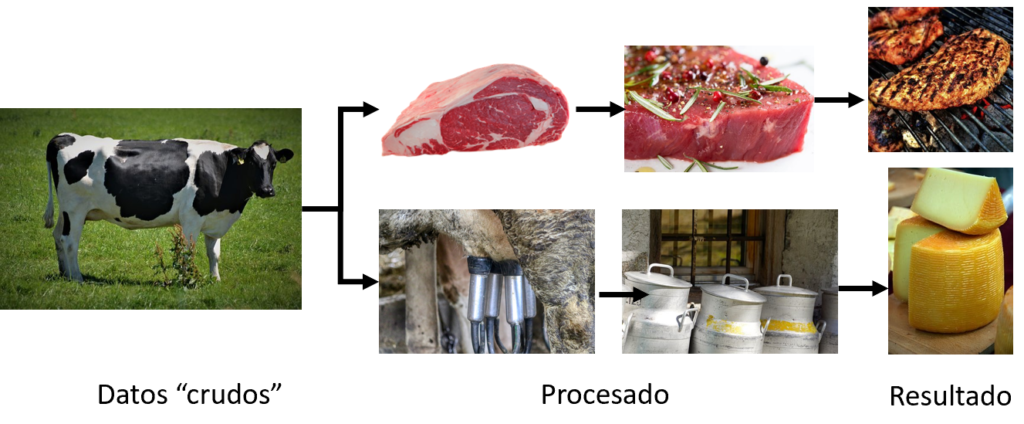
Pues con los datos digitales pasa lo mismo. Éstos se han de tratar adecuadamente dependiendo de la finalidad. De hecho, estudios recientes muestran que los científicos de datos (que estan muy demandados últimamente) pueden emplear hasta el 80% de la vida de un proyecto en el analisis y procesado de los datos. ¡Eso son muchos recursos! Y es a partir de datos «basura», solo obtendremos resultados basuras. Aunque el buen procesado de datos (datos «brillantes»), tampoco nos garantiza resultados brillantes, aunque es necesario para llegar a ellos.
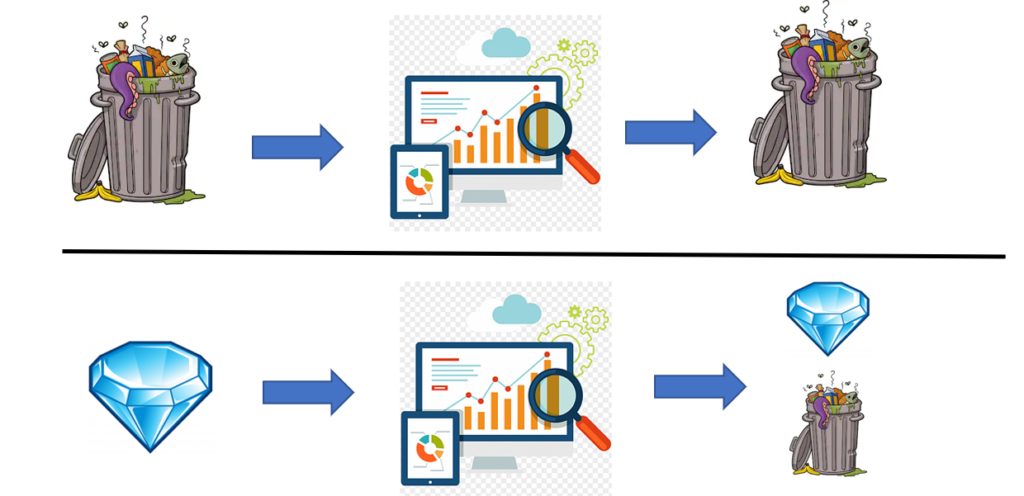
Por ese motivo, no sirve de nada aplicar las últimas tecnologías de inteligéncia artificial si los datos no se entienden y procesan adecuadamente para los fines específicos.
En el caso de las imágenes médicas (mi campo de investigación) pasa lo mismo y lo mostramos recientemente en un artículo que está en acceso abierto «Data preparation for artificial intelligence in medical imaging: A comprehensive guide to open-access platforms and tools»(https://www.sciencedirect.com/science/article/pii/S1120179721000958). También existen otros retos con los datos médicos, como son la seguridad y privacidad, pero eso ya es otra carbonoticia.
Saludos carbonian@s (o carbonautas!).