Pues aquí estoy en el tren de Barcelona a Valencia para dar una charla en una conferencia sobre “Open Source Tools for Imaging Informatics”, algo así como “herramientas libres (sin coste) para la informática de la imagen (médica)”.
Mi idea es hablar sobre la necesidad de datos médicos en la investigación y desarrollo de algoritmos de inteligencia artificial (IA) aplicados a la imagen médica. Para ello, estos datos necesitan una preparación previa que maximice su potencial, por lo que se debería pasar por ciertos métodos/técnicas como se aprecia en la siguiente figura.
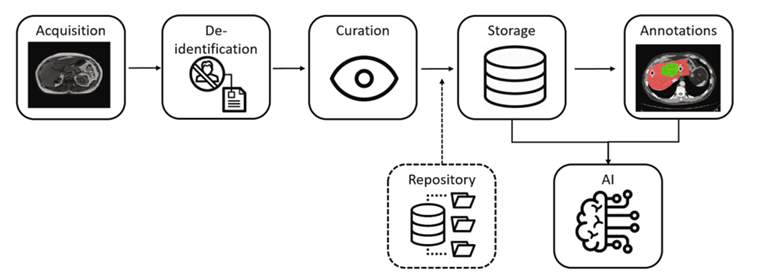
Y es que, para cada uno de estos pasos, existen un sinfín de programas que permiten procesar estos datos “crudos”.
Así que después de adquirir los datos en un escáner, lo primero que se debería hacer para utilizar estos datos en investigación es de-identificarlos (o anonimizarlos). Esta tarea busca la preservación de la privacidad del paciente y consiste básicamente en eliminar toda información personal que pueda relacionar los datos con el paciente (número de historia clínica, nombre, fecha de nacimiento, etc.). De esta forma se pretende mejorar la confianza del paciente en la cesión de datos para su uso en investigación (hecho altamente recomendable).
Este tipo de programas de anonimización deben cumplir la normativa vigente con respecto a la Ley Orgánica de Protección de Datos Personales y garantía de los derechos digitales, que regula y protege la distribución de información personal.
Esta acción de anonimizar imágenes médicas, puede ir más allá de la eliminación de información personal, e incluso se podrían eliminar píxeles o vóxeles de la imagen para impedir la identificación facial de los individuos a partir de fotos de Facebook, por ejemplo. En la siguiente figura vemos un ejemplo de un craneo reconstruido a partir de una resonancia magnética con y sin vóxeles «quemados».
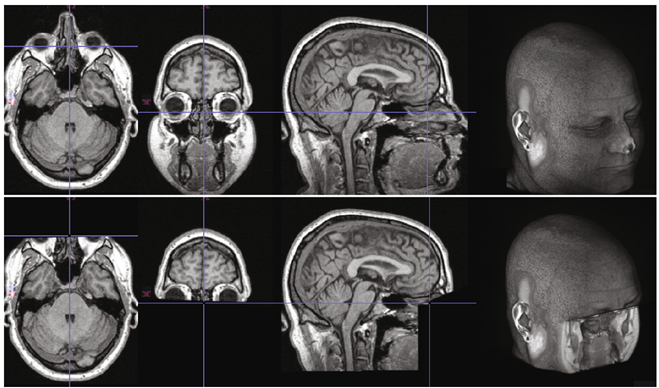
Sin embargo, pueden existir aplicaciones (como la radioterápia en tumores localizados en la cara), dónde este tipo de técnicas dificulten la tarea médica y no se realicen.
La preparación de los datos no acaba aquí, aún tenemos la curación, almacenamiento o la anotación de los datos. Sin embargo, dejaremos esos temas para futuras carbonoticias.
Un saludo carbonian@.